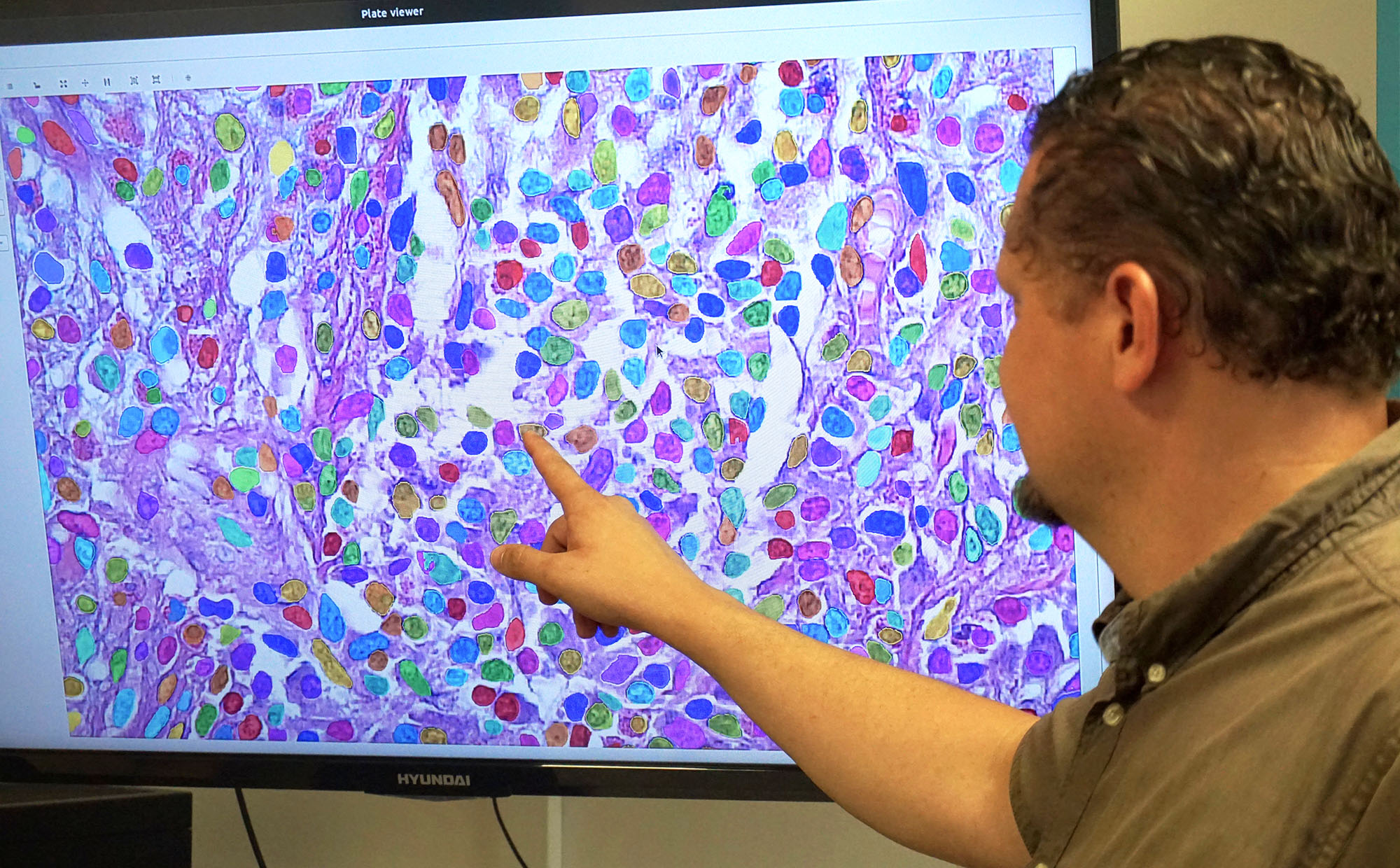
Like diverse GDP measurement approaches across countries: confusions in artificial intelligence-driven image data processing
What if Hungary had the highest GDP in the world? While this scenario is quite unlikely, theoretically, we could jump to the top of the rankings if we measured the national income and performance of countries around the world using slightly different definitions of economic indicators. In fact, this is the case in the field of biological image processing, where the comparative indicators of the algorithms employing artificial intelligence are systematically misinterpreted, raising the possibility that each developer may promote his/her own method(s) as the best. Bioinformatician Péter Horváth and his colleagues at the Biological Research Centre, ELKH, Szeged (BRC) highlight this surprising and generally overlooked practical issue in their recent paper published in Nature Methods, the world’s leading methodology journal.
Fast and efficient data processing requires automation, a process that employs artificial intelligence (AI) and deep learning based algorithms. Thanks to the AI-driven transformation of biological image processing, we are capable of obtaining information from complex biological samples at the cellular and even at the single-cell levels. The algorithms utilized for image analysis tend to process hundreds of thousands or even millions of microscopic images to classify billions of cells precisely, and thereby reveal single-cell variations and deteriorations within the sample. This has critical implications, for instance, in cancer diagnostics and personalized medicine.

Automated biological image processing is competitive and evolves dynamically
The field is extremely competitive today: tens of thousands of bioinformaticians are engaged in improving biological image processing in order to develop increasingly precise and efficient tools. However, designating the “best” method is evaluation- and task-dependent, and the chosen approach determines what and how we can discover in the biological sample. To compare the available methods and select the most appropriate for a given task, we need to use some quantitative metrics. In fact, the literature precisely defines metrics suitable for comparison, however, their interpretation is far from being unequivocal. A metric may have as many as 5-6 different interpretations, says Dominik Hirling, referring to one of the most important findings detailed in their paper. “Again, using the illustrative analogy, it is as if each country interpreted the definition of GDP slightly differently. Thus, while the United States ranks first, China the second, and Japan the third according to one interpretation, India would jump to the leading position from the fifth place, and the US would rank the fourth in another interpretation scenario”, he explains.
What are the implications of metrics’ interpretation?
Similar to the theoretical illustrative analogy above, the research group at BRC examined how the algorithms used for biological image processing compare if they use different interpretations of the comparison metrics. Thus, they evaluated the 2018 Data Science Bowl (DSB) submissions with metrics of similar meaning but slightly differing interpretations. At DSB, encompassing nearly four thousand competing teams, the participants were instructed to develop a microscopic image analysis software which is capable of segmenting each individual cell, even in images never presented to the algorithm before. The algorithms were evaluated by the competition committee, using one or more comparative metrics. However, as it turned out, the results and team rankings would significantly change if an alternative interpretation of a specific metric, also present in the literature, was applied. Therefore, to realistically distinguish between data processing algorithms on a given criterion, it is essential to standardize the interpretations of these comparative metrics, to assure that one can reliably chose the most optimal tool for an intended purpose.
Practical significance
Regarding that biological image processing is indispensable in medical diagnostics and personalized medicine, the matter of misinterpreting the comparative indicators of these algorithms has substantial practical implications. If we are mislead to choose the most appropriate algorithm for a specific task, it will undermine the efficiency of data extraction from the sample. For example, in oncology, merely identifying cancerous cells within the tissue samples is necessary, but not sufficient. As the disease progresses, it becomes increasingly critical to identify any minute changes at the single-cell level, as well as to precisely asses the proportion of these modified tumor cells, since these novel characteristics significantly influence the appropriate therapy of choice.
Closely related to this line of reflection, it is worth mentioning that Hirling and Horváth have recently published another original paper describing a method development (Comput Struct Biotechnol J. 2022;21:742–750) which enhances the efficiency of AI-based cell segmentation by incorporating a mathematical model of shape priors into the algorithms for biological image processing. This means that the algorithm does not “blindly search” among the pixels of the image of the biological sample, but it is instructed to “focus on” specific (i.e. cell-like, elliptoid) shapes. This way the AI algorithm can learn more effectively, which ultimately leads to more efficient image analysis.
Author: Dora Bokor, PharmD
Linkek:
https://www.nature.com/articles/s41592-023-01942-8
https://www.sciencedirect.com/science/article/pii/S2001037022005888?via%3Dihub